Auteur: Maur Bentein
Datum laatste publicatie: 05 maart 2021
Metadata
Bron: https://www.codeproject.com/Articles/1166257/Learning-Machine-Learning-Part-An-Introduction
1 - Een verhaal over Machine Learning
Op het eerste gezicht, kan de term "machine learning" verwarrend zijn. In de computerbranche refereert een machine naar een computer. Deze term is antropomorf, wat aangeeft dat het een technologie is die het mogelijk maakt machines te laten "leren."
Traditioneel gezien moet je een opdracht geven voordat een computer een taak uitvoert; de computer voert het commando uit als per uw input. Echter, dit is niet hoe ML werkt! In ML ontvangt de computer geen inputcommando, maar invoergegevens (data). Dat wil zeggen dat in Machine Learning een computer geprogrammeerd is om gegevens te gebruiken en niet voor het uitvoeren van een taakgerichte opdracht. Statistisch denken is een belangrijk concept dat van groot nut is als je meer over het onderwerp wilt bestuderen. Het is vooral het concept van correlatie, eerder dan causaliteit, dat aan de basis ligt van de praktijk van Machine Learning.
Hier is een verhaal dat perfect Machine Learning illustreert ...
Je hebt waarschijnlijk al een afspraak gemaakt met iemand, en vervolgens zitten wachtten tot de andere persoon zich laat zien. Niet iedereen is punctueel. Als je een persoon ontmoet die altijd te laat is, dan verlies je onvermijdelijk enige tijd door op hem te wachten. Laten we aannemen dat je je vriend John wilt ontmoeten.
John is niet erg punctueel. Deze keer werd je verondersteld om af te spreken bij de Tech Tentoonstelling om 15:00. Net als je de deur uit ging dacht je bij jezelf: "Moet ik nu onmiddellijk vertrekken? Als ik nu vertrek zal ik uiteindelijk zo'n 30 minuten op hem moeten wachten." Denk aan een strategie die je kunt aanspreken om dit "probleem" op te lossen.
Er zijn vele benaderingen voor dit probleem.
- De eerste methode is om gebruikelijke kennis te bezigen die je nodig hebt om dit probleem op te lossen. Helaas heeft nog niemand de oplossing neergeschreven voor het eeuwige probleem van het wachten op chronisch late mensen. Daarom kun je geen oplossing voor dit probleem vanuit de bestaande kennis vinden.
- De tweede methode is om het aan iemand anders te vragen. Echter, niemand kan een oplossing voor dit probleem aanreiken.
- De derde methode is de criterium-methode. Daarbij vraag je jezelf af als je ooit alle criteria hebt bepaald om dit probleem aan te pakken. Bijvoorbeeld: wat andere mensen ook doen, jij zult altijd op tijd aankomt. Het antwoord op die vraag is waarschijnlijk nee.
In feite zijn er andere methoden geschikter dan de drie genoemde. Beschouw deze optie:
Je denkt na over al je ervaringen met John en probeert te komen tot het percentage van de keren dat hij te laat is gekomen. Je gebruikt deze informatie om de kans te voorspellen dat hij deze keer te laat komt. Als deze waarschijnlijkheid een bepaalde grens overschrijdt die je in je gedachten hebt, dan wacht je een tijdje voor je je huis verlaat om naar de tentoonstelling te gaan.
Neem aan dat je John vijf keer hebt ontmoet, en hij is een keer te laat geweest. Dit betekent dat hij 80 procent van de tijd op tijd kwam. Als je mentale afhaak-lijn 70 procent is, dan moet je ervan uitgaan dat John niet te laat zal zijn, en je verlaat het huis op tijd. Echter, als hij in het verleden vier van de vijf keer heeft aangetoond te laat te zijn, dan geeft dit hem een 20 procent kans op tijd aan te komen. In dat geval wacht je een tijdje voordat je je huis verlaat. Deze benadering wordt de empirische methode genoemd. Je maakt gebruik van alle relevante gegevens uit het verleden. Daarom kun je zeggen dat dit besluit gebaseerd is op data.
Het idee van beslissingen op basis van gegevens is in overeenstemming met de gedachte achter Machine Learning. In dit gedachte-experiment heb je alleen de factor "frequentie" beschouwd. Echter, ML-modellen overwegen ten minste twee factoren. Een daarvan is de afhankelijke variabele (het resultaat dat je wilt voorspellen). In het voorbeeld is dit de beslissing of John al dan niet te laat aankomt. De andere factor is de onafhankelijke variabele, welke wordt gebruikt om te voorspellen of John laat zal aankomen. Als je van het "tijdstip" de onafhankelijke variabele maakt, kan het zijn dat al de keren dat John laat is geweest op een vrijdag was, terwijl hij nooit te laat is geweest op de andere dagen van de week.
Daarom zou je een model moeten maken om de kans te simuleren dat John laat zal aankomen op basis van het het feit dat het al dan niet vrijdag is. Het volgende diagram geeft een eenvoudige Machine Learning model dat een beslissingsboom heet.
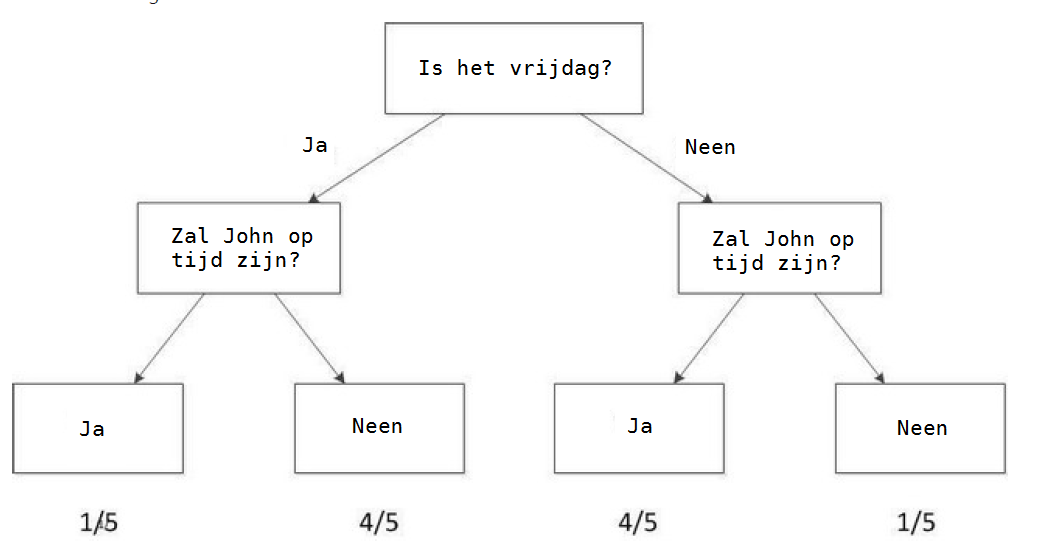
Wanneer je een enkele onafhankelijke variabele overweegt, is het proces vrij eenvoudig. Maar wat als een tweede onafhankelijke variabele wordt toegevoegd? Terug naar het verhaal: laten we zeggen dat een deel van de tijd dat John te laat is gekomen, hij heeft gereden. Misschien is hij een slechte chauffeur of is er veel verkeer. Deze nieuwe informatie kan aan het besluitvormingsproces worden toegevoegd. Nu kun je een complexer model maken dat twee onafhankelijke variabelen en één afhankelijke variabele omvat.
Om de zaken nog ingewikkelder te maken kan slecht weer, zoals regen, een rol spelen bij de laattijdigheid van John. Je hebt dus nu drie onafhankelijke variabelen te overwegen.
Als je wilt voorspellen hoeveel tijd John te laat zal zijn, kun je het aantal minuten dat John te laat was relateren aan de hoeveelheid regen en andere onafhankelijke variabelen om een uniform model te maken. De voorspellingen die door dit model worden gegeven zullen je een idee geven van hoe laat John zal zijn op een bepaalde dag. Dit zal je helpen om de juiste tijd te plannen om je huis te verlaten. In dit laatste geval is een eenvoudige beslissingsboom van weinig nut, omdat het alleen discrete waarden kan voorspellen. Je kunt echter de lineaire regressie-methode gebruiken die in de volgende "post" over Machine Learning Technieken zal worden besproken.
Op dit punt aangekomen kun je besluiten om het modelleerwerk over te laten aan een computer. Bijvoorbeeld zou je kunnen alle onafhankelijke en afhankelijke variabelen invoeren en de computer een model ervan laten genereren. Vervolgens zal je elke keer dat je een afspraak hebt met John aan de computer vragen om te kijken naar de huidige situatie en te bepalen of je het huis later moet verlaten, en zo ja, hoeveel minuten later. Wanneer de computer dit soort proces van ondersteuning van de besluitvorming uitvoert implementeert het een Machine Learning proces.
In de Machine Learning methode maakt een computer gebruik van bestaande gegevens (ervaringen) om een bepaald model (laattijdigheidsregels) te creëren. Dan voorspelt dit model de toekomst (het al dan niet laat aankomen van John).
Door middel van de voorgaande analyses kun je zien dat ML zeer vergelijkbaar is met het normale menselijke denken. Het kan echter veel meer situaties overwegen en meer complexe berekeningen uitvoeren. In feite is het hoofddoel van ML het proces waardoor mensen hun vroegere ervaringen generaliseren te converteren in een proces waarbij een computer gegevens kan analyseren om een model te maken. Deze computermodellen benaderen de wijze waarop de mens subtiele en complexe problemen oplost.
We gaan nu verder met de definitie, omvang, methoden en toepassingen van ML.
2 - Machine Learning: een definitie
In grote lijnen is Machine Learning een methode die machines leermogelijkheden geeft waardoor ze functies kunnen uitvoeren die niet kunnen worden bereikt met rechtstreekse programmering. In de praktijk is Machine Learning een werkwijze die data gebruikt om een model te trainen en het model gebruikt om voorspellingen te doen.
Laten we eens kijken naar een voorbeeld met huizenprijzen.
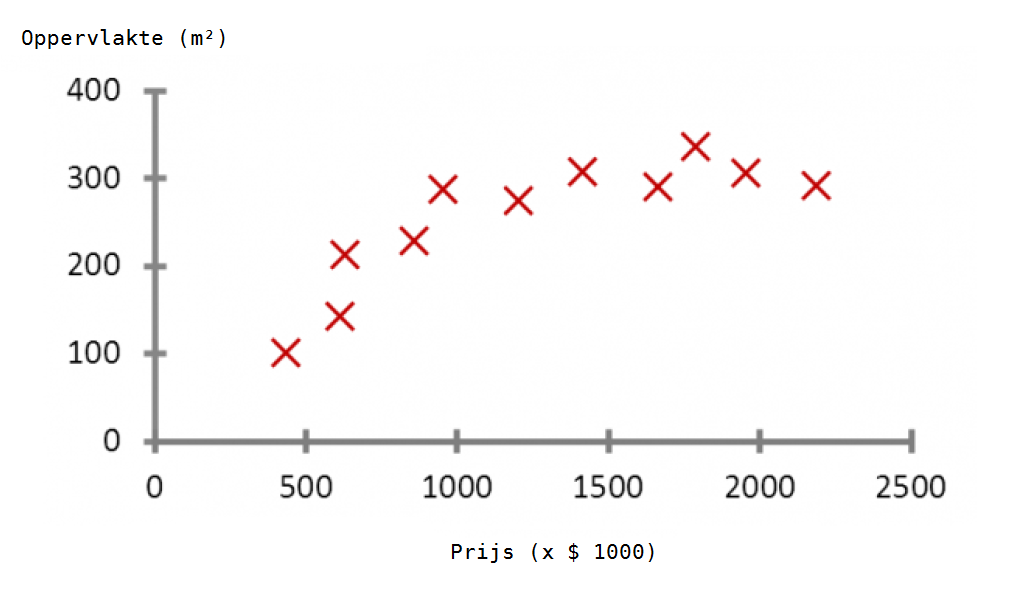
We maken gebruik van verschillende huizenprijzen. Jij bezit een huis dat je wilt verkopen. Tegen welke prijs moet je het oplijsten? Het huis heeft een oppervlakte van 100 vierkante meter. Dus, is de juiste prijs $ 1.000.000? $ 1.200.000? Of $ 1.400.000?
Het is duidelijk dat je een regel nodig hebt die de prijs koppelt aan de omvang van het huis. Maar hoe vind je een dergelijke regel? Gebruik je de gemiddelde huizenprijsgegevens uit de krant of van de online aanbieders? Of kijk je naar prijzen van huizen van vergelijkbare grootte?
Wat je nodig hebt is een rationele regel die de relatie tussen oppervlakte en prijs met de grootst mogelijke variatie weerspiegelt. Omdat je de prijzen van soortgelijke woningen in het gebied hebben onderzocht, heb je al een dataset. Deze dataset bevat oppervlakte en prijs voor huizen van alle soorten en maten. Als je een regel vindt in deze dataset die oppervlakte aan prijs koppelt, dan kun je de juiste prijs voor je huis te vinden.
In feite is het heel gemakkelijk om dergelijke regel te vinden. Je moet enkel een rechte lijn trekken dat het best alle punten in de grafiek verbindt, met de kleinst mogelijke afstand tussen elk punt en de lijn.
Door het vinden van deze rechte lijn heb je de regel die het best de relatie tussen oppervlakte en prijs weerspiegelt. Deze lijn wordt gedefinieerd door de volgende functie: huisprijs = oppervlakte * a + b, waarbij a en b de parameters zijn van de lijn.
Na het vinden van deze parameters kun je de juiste prijs berekenen voor jouw huis.
Neem aan dat a = 0,75 en b = 50 (in $ miljoen). In dit geval is de huisprijs 100 * 0,75 + 50 = $ 1.250.000. Dit resultaat verschilt van de drie opties eerder vermeld: $ 1.000.000 $ 1.200.000, en $ 1.400.000. Omdat deze regel de meeste gevallen in aanmerking neemt is ze statistisch gezien de meest redelijke voorspelling.
Het volgende zijn opmerkingen over dit model.
- Het huisprijsmodel is afhankelijk van de functie die wordt gebruikt om de gegevens te passen. Als een rechte lijn wordt gebruikt, dan gebruik je een lineaire vergelijking om de gegevens te laten passen. Indien je andere lijnen gebruikt, zoals een parabool, dan pas je een ander type lijnvergelijking toe op de gegevens. Veel verschillende algoritmes worden gebruikt in Machine Learning. Er zijn een aantal krachtige algoritmen gebruikt om complexe niet-lineaire modellen te produceren. Hiermee kun je situaties weerspiegelen die niet met een rechte lijn zijn weer te geven.
- Als je meer data hebt, dan zal je model meer situaties in overweging nemen en kan het beter zijn in het voorspellen van nieuwe situaties. Dit belichaamt de "Data is King"-filosofie dat primeert in het ML-gebied. Over het algemeen (maar niet altijd), hoe meer gegevens je beschikbaar hebt, hoe beter de voorspellingen van de modellen gegenereerd door Machine Learning.
Je kunt het proces van het vinden van de best passende lijn gebruiken om naar het gehele Machine Learning proces te kijken. Vooreest moet je historische data bewaren op je computer. Vervolgens verwerk je die data met een Machine Learning algoritme. In Machine Learning taal wordt dit proces "training" genoemd. Het resultaat van deze training kan nieuwe data voorspellen. Dit resultaat wordt als een model beschouwd. Het proces dat gebruikt wordt om nieuwe data te voorspellen wordt "prediction" (voorspelling) genoemd. "Training" en "prediction" zijn beide processen in Machine Learning, terwijl modellen tussentijdse resultaten zijn. "Training" produceert een model, dat op haar beurt "prediction" gidst.
Met behulp van het volgende overzicht kun je het Machine Learning proces met het menselijke ervaringsgerichte denken vergelijken.
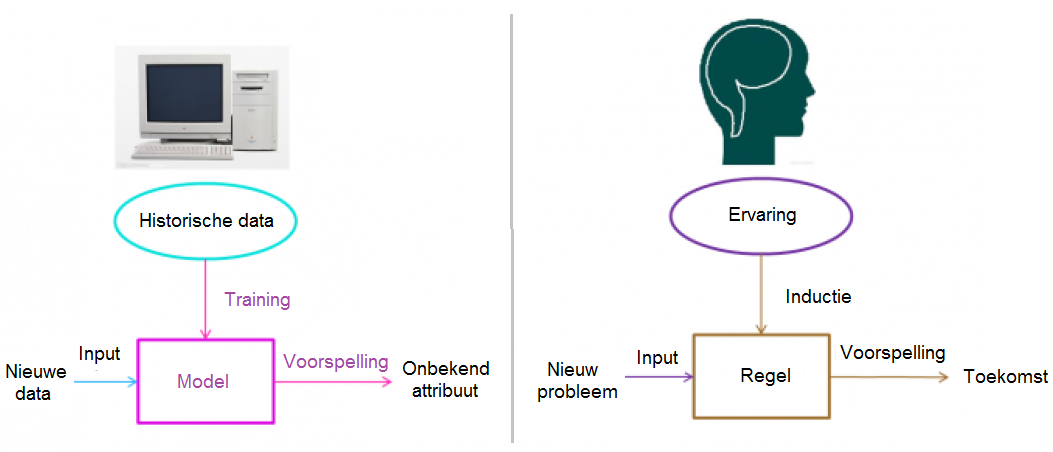
Terwijl je groeit en leeft, verzamel je vele ervaringen. Je generaliseeert regelmatig deze ervaringen en komt tot "regels" over het leven. Wanneer je een onbekend probleem tegenkomt of behoefte hebt om te speculeren over de toekomst, gebruik je die "regels". Deze manier van denken leidt je in je dagelijks leven en werk.
In Machine Learning corresponderen de "training" en "voorspelling" processen met je mentale processen van generalisatie en speculatie. Deze overeenkomst toont dat het concept van de Machine Learning niet complex is. Het is gewoon een simulatie van de leer- en de groei-ervaring van alle mensen. Omdat de resultaten van Machine Learning niet de producten zijn van een programma, lijkt het proces niet op een oorzaak en gevolg-systeem. Integendeel, het maakt gebruik van generalisatie (of inductie) om relevante conclusies te trekken.
Dit brengt ook weer de reden terug voor het bestuderen van de geschiedenis. De geschiedenis kan worden gezien als de samenvatting van de vroegere menselijke ervaringen. Heb je het gezegde gehoord: "De geschiedenis is vaak anders, maar altijd verrassend gelijk"? Door het bestuderen van de geschiedenis kun je algemene regels over mensen en naties vinden en ze gebruiken om je gedrag te leiden. Dit is de grote waarde van de geschiedenis.
3 - Omvang van de Machine Learning
In de vorige paragraaf hebben we gesproken over de definitie van Machine Learning. Laten we nu eens kijken naar het toepassingsgebied.
De bereik van ML lijkt op patroonherkenning, statistisch leren en data mining. Op hetzelfde moment, in combinatie met de technologie van andere gebieden, vormt het interdisciplinaire disciplines zoals spraakherkenning en natuurlijke taalverwerking.
Laten we een aantal van de gebieden die verband houden ML bespreken evenals een blik werpen op enkele van de toepassingsscenario's en omvang van het onderzoek van de ML. Dit zal je begrip over latere discussies over algoritmen en de toepassingsniveau's verhogen.
De volgende afbeelding toont een aantal van de disciplines en onderzoeksgebieden die ML inhouden.

3.1 - Patroonherkenning
Patroonherkenning = Machine Learning
Het belangrijkste verschil tussen patroonherkenning en Machine Learning is dat het eerste concept het leven zag samen met de ontwikkeling van de industriële sector, terwijl het laatste voort komt uit de informatica. In zijn boek "Pattern Recognition & Machine Learning" zegt Christopher M. Bishop: "Patroonherkenning komt van de industriële sector, terwijl de machine learning is afgeleid uit de informatica. In de praktijk echter kunnen ze worden gezien als twee kanten van hetzelfde veld. In de afgelopen tien jaar zijn ze allebei sterk ontwikkeld."
3.2 - Data Mining
Data Mining = Machine Learning + Databases
Recentelijk is het concept van data mining maar al te bekend geworden. Wanneer mensen praten over data mining scheppen ze altijd op over zijn kracht. Zo extraheert het goud uit data, of converteert weggegooide gegevens in waarde. Het is echter niet altijd zeker dat je altijd goud zou vinden als je ernaar ontgint. Dit geldt ook voor data mining. Data mining is gewoon een manier van denken. Je moet proberen om gegevens te delven om kennis te ontdekken. Men moet een diep begrip hebben van de gegevens om patronen te vinden in de gegevens die leiden tot verbeteringen in business. De meeste algoritmen die worden gebruikt in data mining zijn zelflerende algoritmes, geoptimaliseerd in databases.
3.3 - Statistisch Leren
Statistisch Leren = Machine Learning
Statistisch leren is bijna synoniem met ML. Beide disciplines hebben een hoge mate van overlap. Aangezien de meerderheid van de Machine Learning methoden komen uit de statistiek en kunnen worden beschouwd als statistische methoden, zal de ontwikkeling van statistiek Machine Learning bevorderen. Zo wordt het bekende SVM algoritme afgeleid van statistiek. De twee disciplines verschillen echter in zekere mate. Beoefenaars van statistisch leren richten zich op de ontwikkeling en optimalisatie van statistische modellen en hebben de neiging om te leunen in de richting van de wiskunde. Machine Learning beoefenaars zijn echter meer bezig met het vermogen om problemen op te lossen en leunen in de richting van praktische toepassingen. Daarom richten onderzoekers van Machine Learning zich op het verbeteren van de efficiëntie en de nauwkeurigheid van algoritmen die op computers draaien.
3.4 - Computer Visie
Computer Visie = Beeldverwerking + Machine Learning
Beeld processing technologie verwerkt afbeeldingen om ze om te zetten in geschikte input voor Machine Learning modellen. Machine Learning is verantwoordelijk voor het herkennen van patronen in de beelden. Er zijn vele toepassingen van computervisie, zoals Google Image Recognition, handgeschreven tekenherkenning en kentekenherkenning. De toepassingsvooruitzichten voor dit veld zijn veelbelovend en het is een populaire piste van onderzoek. Zoals het nieuwe veld van diep leren zich heeft ontwikkeld binnen Machine Learning heeft het de prestaties van de computertoepassingen voor beeldverwerking aanzienlijk verbeterd. Zo zijn de toekomste ontwikkelingsperspectieven van het veld van computervisie onbeperkt.
3.5 - Spraakherkenning
Spraakherkenning = Voice Processing + Machine Learning
Spraakherkenning is de combinatie van audio processing technologie en Machine Learning. Het wordt zelden zelfstandig gebruikt. Het wordt gecombineerd met "natural language processing" technologie. Een applicatie omvat Apple's stem assistent Siri.
3.6 - Natuurlijke taalverwerking
Natuurlijke taalverwerking = tekstverwerking + Machine Learning
Natuurlijke taalverwerkingstechnologie wordt voornamelijk gebruikt om machines in staat te stellen om natuurlijke menselijke spraak te begrijpen. Het maakt uitgebreid gebruik van compilertheorie technologieën, zoals lexicale en syntax-analyse. Ook op het niveau van begrip gebruiken ze semantisch begrip, ML, en andere technologie. Omdat het omgaat met unieke symbolen, gecreëerd door de mens, is de natuurlijke taalverwerking een constante piste van Machine Learning onderzoek. Volgens Baidu Machine Learning expert Yu Kai: "Om bot te zijn, luisteren, kijken en het maken van geluiden zijn dingen die zelfs honden en katten kunnen doen, maar de taal is uniek voor de mens." De poging om Machine Learning technologie te gebruiken om computers een diep begrip van de menselijke taal te geven is een constante focus in de industrie en de academische wereld geweest.
4 - Conclusie
Nu begrijp je hoe Machine Learning uitbreidingen en toepassingen heeft in vele gebieden. De ontwikkeling van Machine Learning heeft de vooruitgang van diverse intelligente velden om ons dagelijks leven te verbeteren gestimuleerd. Voor informatie over Machine Learning technieken, kijk uit naar het vervolg in de 2de aflevering van deze 3-delige serie: Machine Learning technieken.